在硬盘上组建 RAID 是一个较为通用的技术。近年来由于存储性能的提升和新的存储技术的提出,有一系列学术界工作针对 RAID 新架构进行了研究。本文先简单介绍 RAID 的基本概念,然后分享一些学术界近年来针对 RAID 的科研工作。
RAID 背景
RAID 的产生背景
在 HDD 被广泛用于存储的时代,由于硬件本身的限制,硬盘随机读写效率低下,硬盘损坏可能导致数据丢失。因此,将多块 HDD 组成 HDD 阵列,并在阵列之上设计读写分发策略和容错机制成为了提高存储读写效率和数据容错率的一种常用做法。这就是至今仍在被广泛使用的 RAID(Redundant Array of Independent Disks,独立硬盘冗余阵列)技术。
近年来,随着 SSD 的出现和普及,为了提高 SSD 容错率以及减少 SSD 中垃圾回收等内部活动对读写性能带来的影响,在 SSD 之上使用的 RAID 技术,又称 AFA(All-Flash Array),被工业界所广泛采用。
普通 RAID
下面介绍三种标准 RAID :RAID 0、RAID 1、RAID 5
RAID 0
如下图所示,多块硬盘组成 RAID 0,数据以条带化(stripe)的方式被分到多块盘上。条带指的是多个盘用于存储同一段连续数据的区域,例如下图中的 A1 与 A2 组成了一块条带。这种设计可以在读写数据时同时利用多块盘的带宽。但 RAID 0 存在单盘损坏就无法恢复数据的问题,不提供容错和数据冗余。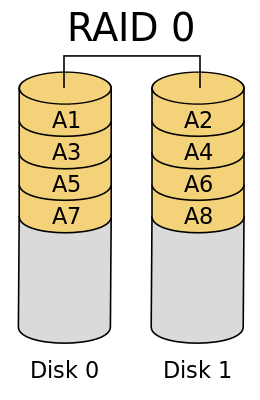
RAID 1
如下图所示,多块硬盘组成 RAID 1,同一份数据被复制成两份分别存在两块盘上。这种设计的好处是,当单块盘发生损坏,可以通过读取另一块盘中同一个条带上的数据进行恢复。同时,读取数据可以利用所有硬盘的读带宽,具有较好的读性能。理论上,假设使用 n 块盘组成 RAID 1,最多能够容忍 (n-1) 块盘的损坏,因此 RAID 1 是容错性最好的一种 RAID。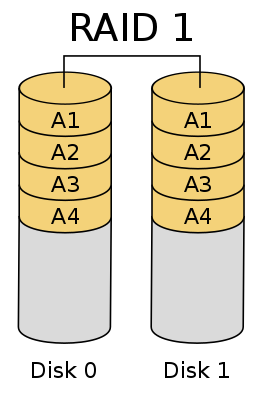
RAID 5
RAID 5 兼顾读写性能、数据安全和存储成本。RAID 5 当中的数据被条带化的存储,类似于 RAID 0。在每一个条带上引入一个 parity block (奇偶校验块),存储校验信息。在写入数据块时需要同时更新对应的 parity。在发生硬盘损坏时,RAID 5 可以通过读取未损坏的盘和 parity 的信息完成数据的恢复。
相比于 RAID 0,RAID 5 具有更好的容错性;相比于 RAID 1,RAID 5 无需写多块相同数据,只需更新目标数据块和 parity 块,具有较好的写性能;同时 RAID 5 在每一个条带上只会利用 1 个块作为冗余的校验信息存储,相比于 RAID 1 来说保证相当的容错性的同时又节省了更多的存储空间。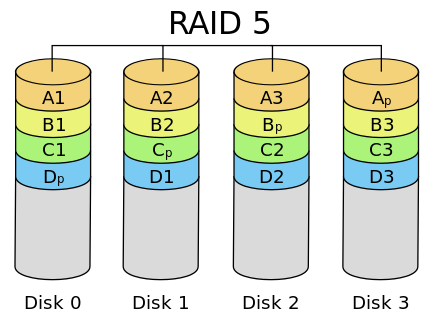
另类 RAID
JBOD
JBOD(Just a Bunch Of Disks)简单地将多个硬盘组合进行使用,不使用数据条带化。相比于 RAID 0,读写连续的数据大多落在同一块盘上,无法利用多硬盘的带宽优势。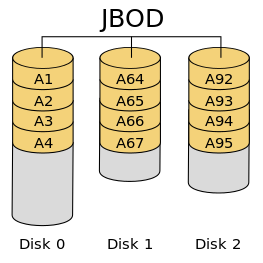
RAID 10
RAID 10 在多个 RAID 1 组之上组成 RAID 0。数据先进行条带化,再进行镜像,这使其能够获得 RAID 0 带来的读写性能优势以及 RAID 1 带来的容错性。
与之相对的,存在 RAID 01 的架构,即先对数据进行镜像,再进行条带化。然而,RAID 01 底层的一组 RAID 0 中只要有一块盘损坏,整个组将无法对外服务,这使得 RAID 01 可用性要比 RAID 10 差。因此一般零售主板只支持 RAID 10 而不支持 RAID 01。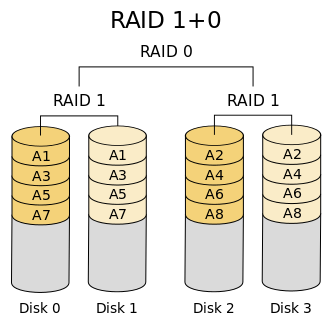
部署方法
Linux 的 mdadm 实用工具提供了软件 RAID 的实现。Linux 中实现了 md[1](multiple devices,多设备)驱动器,用于在软件层面完成 RAID 的功能,例如对数据进行镜像或计算 parity。由于这类软件 RAID 需要占用一些 CPU 资源来完成 RAID 架构所需要的计算任务,实际的读写性能会受到一定影响。
一类 RAID 架构的出现通常先有软件实现,而当硬件厂商发现这类 RAID 被广泛使用时,就会在硬件上设计出更高效的实现。硬件 RAID 相比于软件 RAID 更加节省 CPU 资源并且能够完成更高效的数据读写和保护。
然而在实际使用上,并非硬件实现能够完胜软件实现。使用软件 RAID 反而会有更好的兼容性,容易监控磁盘状态以及更容易将硬盘迁移到不同的机器上。可以参考 lwn 对软硬件 RAID 实现的讨论[2]。
RAID 前沿研究
异构 RAID
在相同的存储介质上组成 RAID 从而提高读写效率或是数据可靠性已经是一个被广泛使用的技术。而在存储相关的学术研究当中,有许多工作将 HDD、SSD 甚至是 NVM 等不同存储介质组合成为 RAID 从而获得更多性能或者容错性的优势。下面将对这些研究做一些设计思想上的介绍。
数据缓存架构
价格不同、读写效率不同的多种存储介质通常可以靠 caching(缓存) 或者 tiering(分层)等设计来完成更高效的存储[3]。
在 caching 的设计当中,小容量的快存储作为大容量慢存储的缓存层,以此来提高热数据的访问效率。例如,小块 SSD 可以作为大容量 HDD 的缓存,这相比于相同容量的单层快存储,节省了购买资金的开销;相比于单层慢存储,又获得了更好的读写性能。Linux 中软件实现的 EnhanceIO[4]、Bcache[5]、dm-cache[6] 与 Flashcache[7],以及硬件实现的 HPE SmartCache[8] 都采用了这种架构,使用小块 SSD 作为 HDD 的缓存,提高性能。使用 mdadm 工具也可以简单的配置这种缓存架构。然而,当缓存抖动现象(即由于快存储容量不足而导致的频繁的数据换入换出)严重时,两层存储之间交换的负载会增加,从而影响到存储的整体性能表现。
在 tiering 的设计当中,各层的存储都可以被上层请求直接访问,在后台异步进行冷热数据的迁移。由于其数据重新布局的频率相比于 caching 低很多,整体的数据布局可能相对处于较差的状态,对于频繁访问热点数据的工作负载不太友好。发表在 ISPA ‘12 的 PASS[9] 论文基于这种思路,提出 SSD 同步提供 IO 服务,数据异步镜像到 HDD 的架构,从而掩盖掉直接读写 HDD 的时延,并能利用 HDD 的大容量优势。
实际部署异构存储设备通常需要根据工作负载以及硬件开销等需求在上述两种常见的架构中进行权衡和选型。同时,考虑到 SSD 作为频繁读写的缓存可能会很快写坏,Linux 中各个磁盘缓存机制也支持将多个小块的 SSD 缓存组成 RAID 1,从而避免 SSD 频繁读写导致写坏和数据丢失的问题。但这只能算是暂缓之计,SSD 当中垃圾回收等内部活动所带来的性能下降需要更完善的架构设计才能够解决。因此,最近几年不少学术界工作针对混用 SSD 和 HDD 可能会导致一系列的性能下降问题,做了相应的架构设计进行解决。
在 FAST ‘12 的一篇论文中,Oh 等人[10]提出在 SSD 作为 HDD 的缓存的架构下,不能简单的将整块 SSD 盘作为可读写的缓存,否则可能导致预留给 SSD 做垃圾回收的空间不够,在垃圾回收实际进行时导致严重的性能下降。因此这篇论文将 SSD 拆为读、写以及内存回收三块区域,并构建模型得出最佳的分配方式,减少 SSD 内部活动给其作为缓存的性能带来的影响。
发表在 FAST ‘20 的 BCW[11] 也指出系统对 SSD 和 HDD 的利用上存在明显的不均衡现象,SSD 经常被过度使用而 HDD 的利用率却相对较低。例如,在 caching 的架构下,写密集的工作负载都落在 SSD 上,导致垃圾回收被频繁出发,增加尾时延;同时会导致 SSD 更容易被写穿,影响使用寿命;在 SSD 承受高负载的情况下,HDD 的写带宽却只有较低的利用率。为了解决该问题,BCW 这篇论文提出一个发现:HDD 内部的缓冲机制使得其写操作的延时呈周期变化,在写操作落在 HDD 缓冲时,延时只有微秒级别,这和写 SSD 的延时非常接近。因此在 BCW 设计中,一部分写操作被引导到 HDD 上,从而降低 SSD 的负载。BCW 所实现的 I/O 控制器会根据其建立好的模型先预测 HDD 下一次写入的情况,在它能够提供微秒级延时时,将请求交由 HDD 进行处理。
元数据缓存架构
在基于 parity 保证数据可靠性的 RAID 架构当中,小块、频繁的数据写入会导致 parity 也被频繁读取、计算、写入 (read-compute-write process,读取-计算-写入过程)。这会导致每次写入数据时额外的读 parity、计算 parity 的操作使得写入的时延增加。
1993年 ISCA 会议的一篇文章 Parity Logging Overcoming the Small Write Problem in Redundant Disk Arrays[12] 提出 parity 应该以 logging 的方式追加写入到 HDD 上,而后再批量更新到实际的 parity 块中,这样就能利用 HDD 的顺序写较好的性能减轻 parity 频繁更新的问题。
发表在 ICPP ‘16 的文章 Improving RAID performance using an endurable SSD cache[13] 提出使用 SSD 作为数据和 parity 的缓存,从而将重复使用到的 parity 留在缓存中,减少了对底层 HDD 的写入频率。
Purity[14], Flash-Aware RAID[15] 两篇文章使用读写性能更好的 NVRAM 来作为数据和 parity 的缓存,从而达到更好的性能。
AFA
RAID 的初衷是用于提高 HDD 的读写性能和容错性。在本文一开始所提到的 AFA(All-Flash Array)直接将原来用于 HDD 的 RAID 技术直接迁移到 SSD 阵列上使用,这导致 SSD 本身的一些特性使得 RAID 的优势受到限制。例如,如果使用的是 AFA,那么上述 parity 的读取-计算-写入过程同时还会导致写放大问题,即对 parity 块的频繁写入会提高 SSD 做垃圾回收的频率以及降低 SSD 盘的寿命。
针对此问题,Differential RAID [16] 对 SSD 盘的寿命进行建模,根据估计的 SSD 剩余寿命将 parity 进行在各个 SSD 上进行重分布,从而达到负载均衡的效果,避免 parity 的频繁更新导致单个盘迅速写坏。
FAST ‘16 会议中的 ToleRAID [17] 发现 SSD 垃圾回收等内部活动在单个 SSD 上所表现出来的尾时延会在 AFA 的架构下被进一步放大。ToleRAID 针对尾时延问题进行了解决,其中一个核心的避免尾时延的机制是,在读取一块数据的同时发出一个额外的对 parity 块的读取请求,并通过 parity 重构出当前要读的这块数据,使用额外的读请求数和计算开销对冲掉了原本单个读取数据拉高尾时延的风险。
发表在今年 FAST 会议上的 FusionRAID [18] 由清华大学的郑纬民团队完成,个人认为是目前 RAID 前沿设计的集大成者。通过混合有效的 RAID 架构,提高了 AFA 的性能,减轻了 SSD 本身垃圾回收、易写坏等问题带来的整体性能影响。其整体架构如下图所示,FusionRAID 在实际的 SSD 池之上引入了一个逻辑区域,利用逻辑区域到物理设备的映射的设计,使得请求被均衡的发到所有 SSD 上,从而避免了单个 SSD 盘的内部活动对整个阵列带来的尾时延问题。FusionRAID 将写入请求分为两个阶段完成:先写入 RAID1 区域(图中 replicated area),再后台转换为 RAID5/6 (图中 RAID area)。前者避免了 parity 频繁更新的问题,后者又减少了数据冗余并提高了空间利用率。这里有个小优化是 RAID1 区域的结构可以是已经为到 RAID5/6 的转换所准备好的,在需要转换时无需做全量的数据拷贝,在原地完成转换。优化实现细节详见论文。此外,FusionRAID 还引入了尾时延检查和请求重定向的优化,在 SSD 盘不可相应的时候将请求转发到其他盘上,从而避免最坏情况下的尾时延显著放大问题。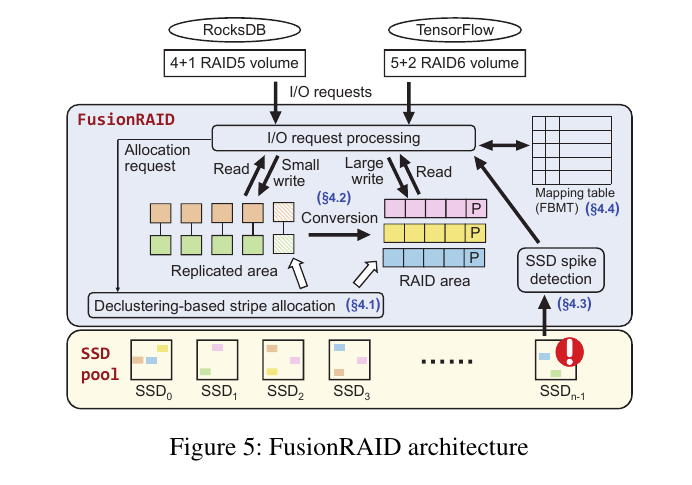
总结
RAID 是将多个存储设备进行组合从而提高存储整体的读写效率和数据可靠性的一种常用技术。在工业界 AFA 被广泛的使用,异构设备之上的 RAID 设计也成为了学术研究的一个热门领域。RAID 和大多数分布式系统的本质目的一样,通过组合数量较多硬件资源而提高整体性能和可靠性。因此基于 RAID 的架构设计常常和分布式系统当中的一些设计类似。
参考链接
[1] https://linux.die.net/man/8/mdadm
[2] Linux Software RAID > Hardware RAID, https://lwn.net/Articles/666226/
[3] Hybrid storage systems: A survey of architectures and algorithms, https://ieeexplore.ieee.org/stamp/stamp.jsp?arnumber=8283744
[4] EnhanceIO, https://github.com/stec-inc/EnhanceIO
[5] bcache, https://www.kernel.org/doc/Documentation/bcache.txt
[6] dm-cache, https://www.kernel.org/doc/Documentation/device-mapper/cache.txt
[7] Flashcache, https://github.com/facebookarchive/flashcache
[8] HPE SmartCache, https://buy.hpe.com/us/en/software/server-management-software/server-management-software/smart-array-management-software/hpe-smart-array-sr-smartcache/p/5364342
[9] PASS: A Hybrid Storage System for Performance-Synchronization Tradeoffs Using SSDs (ISPA ‘12)
[10] Caching less for better performance: Balancing cache size and update cost of flash memory cache in hybrid storage systems (FAST ‘12)
[11] BCW: Buffer-Controlled Writes to HDDs for SSD-HDD Hybrid Storage Server (FAST ‘20)
[12] Parity Logging Overcoming the Small Write Problem in Redundant Disk Arrays (ISCA ‘93)
[13] Improving RAID performance using an endurable SSD cache (ICPP ‘16)
[14] Purity: Building Fast, Highly-Available Enterprise Flash Storage from Commodity Components (SIGMOD ‘15)
[15] Flash-aware RAID techniques for dependable and high-performance flash memory SSD (TC ‘11)
[16] Differential RAID: Rethinking RAID for SSD reliability (TOS ‘10)
[17] The Tail at Store: A Revelation from Millions of Hours of Disk and SSD Deployments (FAST ‘16)
[18] FusionRAID: Achieving Consistent Low Latency for Commodity SSD Arrays (FAST ‘21)